原文链接:http://www.juzicode.com/archives/106
1 下载python解释器版本
本教程以windows系统为例进行讲解,我们首先需要根据windows操作系统的bit版本决定使用python解释器的bit版本。在win10和win7系统中进入“控制面板\所有控制面板项\系统”,找到“系统类型”项,确定操作系统是32位(32bit)还是64位(64bit)。 如果windows系统是64位系统,可以选择下载64bit或者32bit版本的python,如果windows系统是32位系统,则只能下载32bit版本的python。在官网链接上可以根据文件名称来判断,如果包含了“x86-64”表示是64bit版本,如果只有“x86”字样则是32bit版本。
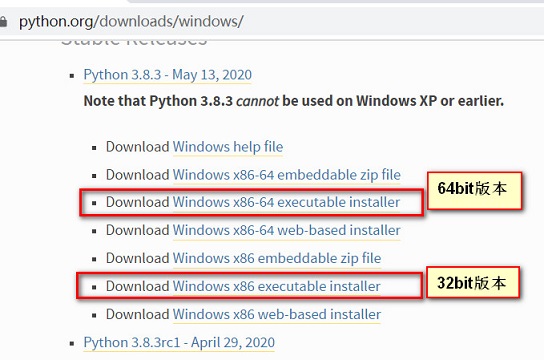
下载python3.8 64bit版本过程:
2 安装python解释器
找到下载到电脑的python解释器可执行文件,双击运行开始安装,在弹框中先勾选“Add Python 3.8 to PATH”,再选择“Customize installation”。注意这里,只有在勾选“Add Python 3.8 to PATH”选项后,在命令行界面下输入“python”或者“python.exe”才会自动查找到你刚才安装的解释器exe文件,另外后面使用pip工具安装库文件才会安装到正确的路径。

安装python3.8 64bit过程:
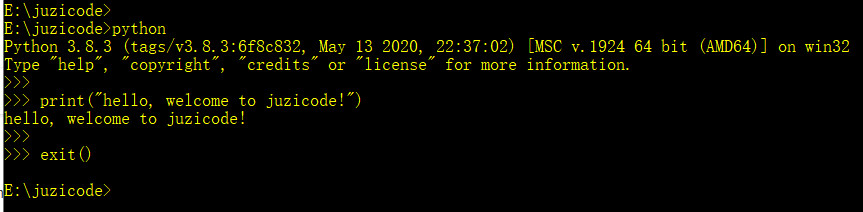
静待安装完成后,来验证下解释器是否安装正确:同时按下键盘徽标+R输入“cmd”后回车启动命令行,在弹出的命令行窗口中输入python或者python.exe后回车,可以看到刚才安装的3.8.3的版本号,表示python已经安装成功。

3 你的第一行python代码
在cmd执行python的窗口的提示符”>>>”后面输入你的第一行python代码:print(“hello, welcome to juzicode!”),按回车后如果打印出“hello, welcome to juzicode!” 则表示执行成功。 恭喜你,你的双脚已经跨进了python世界的大门!
4 notepad++代码编辑器
Python代码的执行可以像在上一节那样在命令行下的交互式输入,但是使用这种方法你敲过的代码不能保存,第二次执行时又要重新敲一遍,而使用文件存储代码的方法更方便,所以需要用到代码编辑器。 Notepad++是一款非常优秀、轻量的代码编辑器,开始时我们并不需要使用更”重量”的eclipse或者pycharm,以免陷入到编辑器的使用“泥潭”中。
5 命令行启动文件
在windows下每次徽标+R启动“cmd”命令行后需要切换路径到写好的python文件路径下,切换路径非常麻烦,这里介绍一个简便的方法,在你常用的工作文件夹目录下,命名一个“启动命令行.bat”的文件,用notepad++或者记事本打开,输入“cmd”三个字符后保存关闭,以后每次双击该bat文件,就会自动切换到该文件所在的目录。
更多启动命令行方法戳这里:《计算机基础–Windows PATH变量、命令行、搜索路径》
6 你的第一个py文件
在你的工作目录下创建一个myfisrt.py文件,用notepad++打开,输入如下代码:
print('hello, welcome to juzicode!')
print('this is my first python file')然后在cmd命令行下切换到该myfirst.py文件的目录下,输入python myfisrt.py后回车,看到双引号内的字符串内容,说明文件执行成功!

myfirst.py:https://github.com/juzicode00/py3study/blob/master/01-myfirst/myfisrt.py
windows系统cmd执行python文件:
7 文件编码格式
在上一节的例子中,print函数打印的内容都是英文,目前看来一切都好,接下来我们试着输出中文,看下情况如何。进入到01-myfirst目录下,新建一个 “mysecond-中文.py” 文件,用notepad++打开,输入如下内容后保存:
print('你好,欢迎来到桔子code!')
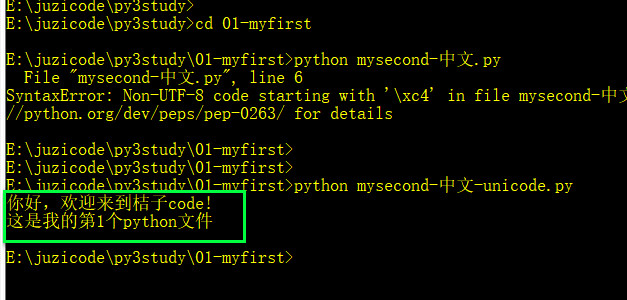
print('这是我的第1个python文件')然后在命令行下输入 “python mysecond-中文.py”执行这个py文件,可以看到提示SyntaxError,提示文件不是utf-8编码发生了错误:

解决这个问题的方法是打开该文件,选择转换为UTF-8 无BOM编码格式后,另存为“mysecond-中文-unicode.py”。
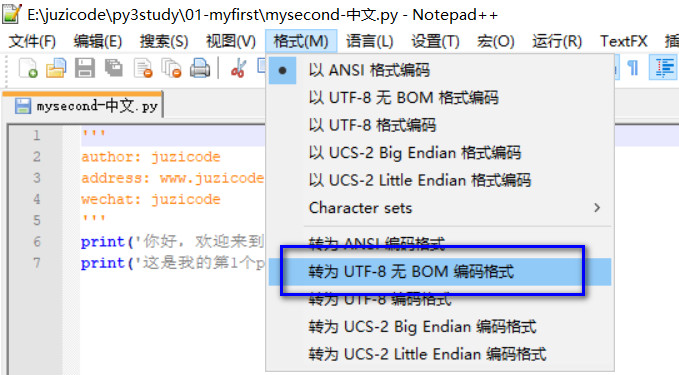
这时再执行这个新的文件,前面报错的问题解决了,记住后面在用notepad++新建py文件时,要选择“转为UTF-8无BOM编码格式”。
Python解释器默认识别的文件编码方式是utf-8,所以在源程序中没有指明编码方式时,解释器认为代码文件用的是utf-8格式编码,如果文件实际是用其他编码方式比如中文操作系统中默认是gbk格式的,这样就会导致解释器抛异常。如果在源程序文件的首行用”#coding=gbk”或者”#coding=cp936#声明文件编码方式是gbk格式,并且文件实际也是按照gbk编码保存的(notepad++选择保存为ascii编码格式),文件执行就不会有问题。
#coding=gbk
stri='桔子code'
print(stri)#coding=cp936
stri='桔子code'
print(stri)声明文件编码类型的变化形式:
# coding:cp936
# encoding:gbk本文对应的示例代码:https://github.com/juzicode00/py3study/tree/master/01-myfirst
终于搞明白官网上下载文件名称的差异了