原文链接:http://www.juzicode.com/python-note-write-file-with-linux-style-crlf-in-windows
为了描述方便,下文\n等价于LF字符,\r等价于CR字符。
Python中open方法创建和写入文件时,写入一个\n(LF)表示要写入一个换行符,但是在windows系统中,默认除了会写入一个\n(LF)字符,还会自动添加一个\r(CR)字符:
#VX公众号: 桔子code / juzicode.com
with open('test.txt','w') as pf:
pf.write('juzicode.com\n')
pf.write('vx:桔子code\n')
with open('test2.txt','w') as pf:
pf.write('juzicode.com\r\n')
pf.write('vx:桔子code\r\n')上述代码运行后,用notepad++打开这2个文件,菜单栏设置“视图–显示符号–显示行尾符”:
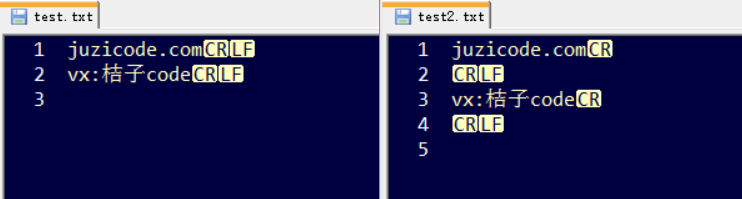
代码中test.txt写入一行字符串的末尾只有一个\n字符,但是生成的文件实际写入了 \r\n 2个字符,代码中test2.txt写入一行字符串的末尾有2个 \r\n 字符,但是实际写入了 \r\r\n 3个字符,也就是会自动添加进一个\r字符。
这时就会存在这样的问题:在某些情况下并不希望存在自动添加的\r字符,比如在Tesseract-OCR5.0字体训练以及提高准确率、提升训练效率的方法 一文中我们看到生成的训练清单文件不能包含 \r 换行符,如果用Python写文件要如何实现呢?
一个方法是将文件按wb方式打开,并且将要写入的字符转换成bytes字节写入:
#VX公众号: 桔子code / juzicode.com
with open('test.txt','wb') as pf:
pf.write(bytes('juzicode.com\n',encoding='utf-8'))
pf.write(bytes('vx:桔子code\n',encoding='utf-8'))
with open('test2.txt','wb') as pf:
pf.write(bytes('juzicode.com\r\n',encoding='utf-8'))
pf.write(bytes('vx:桔子code\r\n',encoding='utf-8'))运行结果:
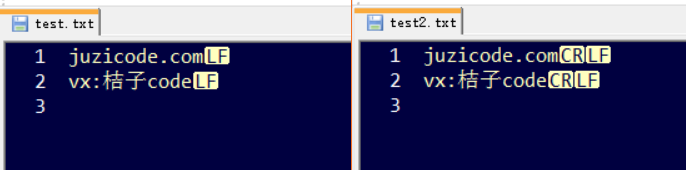
这种情况下并没有自动添加\r字符了。
另外还可以在创建文件对象时入手,从open()方法的说明文档可以看到,open()方法是可以带newline入参的:

所以也可以在创建文件实例时,传入newline入参强制设定newline=’\n’:
#VX公众号: 桔子code / juzicode.com
with open('test.txt','w',newline='\n') as pf:
pf.write('构建文件对象时传入newline\n')
pf.write('juzicode.com\n')
pf.write('vx:桔子code\n')
with open('test2.txt','w',newline='\n') as pf:
pf.write('构建文件对象时传入newline\r\n')
pf.write('juzicode.com\r\n')
pf.write('vx:桔子code\r\n')运行结果:
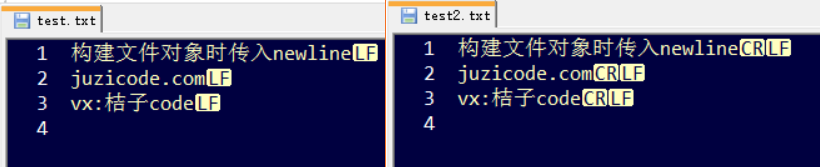
这种方式和按照二进制写入的效果是一样的,也没有多余的 \r 符号。
小伙伴们,你get到了吗?