原文链接: http://www.juzicode.com/python-tutorial-file-csv/
csv的英文全称是Comma-Separated Values,直译过来就是“逗号分隔值”,名称简单粗暴易懂,最核心的意思就是每行记录值之间用逗号分隔。
csv格式没有一种强制性的标准性文档,只是在ietf的RFC4180中有一个建议性的规范,详细介绍可以在这里了解: https://www.ietf.org/rfc/rfc4180.txt 。最核心的几条建议:1.每条记录 (record) 在一个单独的行中,每条记录之间用CRLF换行符间隔;2. 最后一条记录没有CRLF;3.可以有一个可选的header在第一行,也是用CRLF结尾;4. header和每个记录必须有1个或多个域(field),这些域用逗号分隔; 每个记录必须有相同数量的值(直观理解就是这些的记录的列的数目必须是一样的),每条记录的最后不能用逗号,必须是CRLF,如果是最后一条记录则为空(如果有逗号就说明最后还应有一列数据)5.每个域可以用双引号或者不用双引号包含,如果域中没有被双引号包含,则域中不能出现双引号;6.如果域中包含CRLF,双引号,逗号这些特别用途的符号,则必须包含在双引号中;7.如果有一对双引号用来包含域,如果域内用双引号必须是连续的2个双引号表示一个双引号。
啰啰嗦嗦这么多,不如直接上例子更直接,可以打开wps或者office,新建一个工作簿,在表格中输入一些字符,然后”另存为”选择保存为csv格式(注意不要先保存excel文件再另存为csv文件,这样不一定能得到想要的结果)。
![]()
保存文件后再用notepad++打开这个csv文件,对比观察其在notepad中的存储形式。
![]()
通过上图可以看出,第1行数据是所谓的header,其形式上和第2行的记录并没有任何差别。第2行是中规中矩的3个域,每个域之间用2个逗号分隔了。第3行数据在左边的表格形式中可以看出其第3列是空的,但是保存时必须为这一列保留空间,所以第2个逗号后面是个空的内容。第4行数据则是复杂的双引号和逗号的使用,可以看到第2列中字母A前面有个双引号,根据rfc4180第6、第7条,这个双引号前必须要加一个双引号,而且要在最外侧加一对双引号包含起来;第4行的第3个数据中有逗号, 根据rfc4180第6条,这个域的最外侧也要加一对双引号包含。第5行在左侧表格中看起来是一行空的数据,所以用2个逗号分隔空的字符串。第6行的第3列是个数值型的4180,但是csv文件并不接受数值型的数据,保存的仍然是字符串形式的“4180”。
1 csv文件读取
1.1 reader()方法
首先用open()函数创建一个文件对象,再将这个文件对象传入到csv.reader()方法中,读出的数据就是csv文件的记录组成的一个list:
import csv
with open('example.csv', 'r', encoding = 'utf-8') as f:
records = csv.reader(f)
for rec in records:
print(rec)
==========结果:
['header1', 'hearder2', 'header3']
['www', 'juzicode', 'com']
['weixin', 'juzicode', '']
['abc', '"Abc', 'A,BC']
['', '', '']
['etif', 'com', '4180']1.2 DictReader()方法
也是先用open()函数创建一个文件对象,再将这个文件对象传入到csv.DictReader()方法中,读出的数据就是csv文件的记录组成的csv.DictReader实例,这是一个可迭代对象,它的每个元素用第一行的hearder值作为字典key值获取到每一列的域数据:
print('-----欢迎来到www.juzicode.com')
print('-----公众号: juzicode/桔子code\n')
import csv
with open('example.csv', 'r', encoding = 'utf-8') as f:
reader = csv.DictReader(f)
print('type(reader):',type(reader))
for row in reader:
print(row['header1'],row['header2'],row['header3'])
==========结果:
type(reader): <class 'csv.DictReader'>
www juzicode com
weixin juzicode
abc "Abc A,BC
etif com 41802 csv文件写入
2.1 writer()方法
step1:首先用open()函数写模式创建一个文件对象;step2:将这个文件对象传入到csv.writer():中创建一个cvs写对象writer_obj,step3:用写入的数据组成list传入到 writer_obj.writerow()方法中:
import csv
with open('example-write.csv', 'w', encoding = 'utf-8',newline='') as f:
writer_obj= csv.writer(f) #创建写csv对象
records=['h1','h2','h3']
writer_obj.writerow(records) #写入记录
records=['www','juzicode','com']
writer_obj.writerow(records) #写入记录
records=['vx:','桔子code']
writer_obj.writerow(records) #写入记录
【注意】用open()函数创建文件对象时,需要声明newline为空,这样创建的文件才不会有多余的空行,下图是使用newline=”与不使用的对比效果:
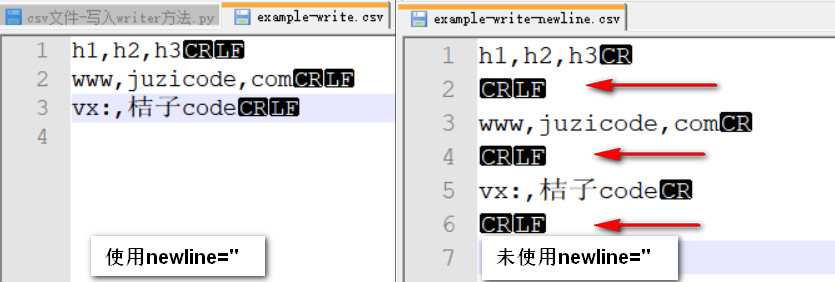
是否使用newline=”生成的csv文件,再用csv模块读出之后也是有区别的:
import csv
print('设置newline为空')
with open('example-write.csv', 'w', encoding = 'utf-8',newline='') as f:
writer_obj = csv.writer(f) #创建写csv对象
records=['h1','h2','h3']
writer_obj.writerow(records) #写入记录
records=['www','juzicode','com']
writer_obj.writerow(records) #写入记录
records=['vx:','桔子code']
writer_obj.writerow(records) #写入记录
with open('example-write.csv', 'r', encoding = 'utf-8') as f:
records = csv.reader(f)
for rec in records:
print(rec)
print(' 不 设置newline为空')
with open('example-write-newline.csv', 'w', encoding = 'utf-8') as f:
writer_obj = csv.writer(f) #创建写csv对象
records=['h1','h2','h3']
writer_obj.writerow(records) #写入记录
records=['www','juzicode','com']
writer_obj.writerow(records) #写入记录
records=['vx:','桔子code']
writer_obj.writerow(records) #写入记录
with open('example-write-newline.csv', 'r', encoding = 'utf-8') as f:
records = csv.reader(f)
for rec in records:
print(rec)
===========结果==========:
设置newline为空
['h1', 'h2', 'h3']
['www', 'juzicode', 'com']
['vx:', '桔子code']
不 设置newline为空
['h1', 'h2', 'h3']
[]
['www', 'juzicode', 'com']
[]
['vx:', '桔子code']
[]2.1 DictWriter()方法
用DictWriter()方法创建对象时,需要同时传入文件对象和表头,使用writeheader()方法写表头,写入的记录需要用表头的元素作为字典的key值,记录的域的值作为字典的value组成一个字典,如果使用writerow()每次写入一行记录,入参是单个字典,如果使用writerows(),则可以写入多行记录,入参是字典组成的list。
import csv
print('设置newline为空')
with open('example-DictWrite.csv', 'w', encoding = 'utf-8',newline='') as f: #step1 创建文件对象
headers=['h1','h2','h3']
writer_obj = csv.DictWriter(f,headers) #step2 创建写csv对象
writer_obj.writeheader() #step3 写表头,不需要传入headers,在创建对象时已传入
record = {'h1':'www','h2':'juzicode','h3':'com'}
writer_obj.writerow(record) #step4 写单行
records = [{'h1':'WWW','h2':'JUZICODE','h3':'COM'},
{'h1':'vx:','h2':'桔子code'},
{'h1':'vx:','h2':'juzicode','h3':'csvtest'},
]
writer_obj.writerows(records) #step4.2 写多行
with open('example-DictWrite.csv', 'r', encoding = 'utf-8') as f:
records = csv.reader(f)
for rec in records:
print(rec)
==========结果=========:
-----欢迎来到www.juzicode.com
-----公众号: juzicode/桔子code
设置newline为空
['h1', 'h2', 'h3']
['www', 'juzicode', 'com']
['WWW', 'JUZICODE', 'COM']
['vx:', '桔子code', '']
['vx:', 'juzicode', 'csvtest']
使用DictWriter写表时,会对写入的字典和表头进行对比,下面的例子是将表头减少一个元素h3,但是写入的字典值中却包含了h3,调用writerow()方法时抛ValueError异常提示不存在h3:
总结: 1、可以使用csv.reader()和csv.DictReader()方法创建读取文件对象, 使用csv.writer()和csv.DictWriter()方法创建写文件对象, 其初始化入参为open()函数创建的文件对象; 2、reader()方法获取到的是以多条记录构成的list,其中每条记录由域构成的list。 3、DictReader()方法获取的也是多个记录,这些记录中的域可以通过字典的方法获取。 4、writer()创建的对象通过writerow()写入由域构成的单条记录。 5、DictWriter()创建的对象通过writeheader()写入表头(第一行),writerow()写入表头和域组成的单个字典,也可以使用writerows()写入表头和域组成的字典构成的list。