原文链接:http://www.juzicode.com/python-module-openpyxl
在之前的xlwt和xlrd的文章中我们介绍了Excel访问的2个工具,它们分别只能对Excel文件进行写或者读,今天再介绍一个可以对Excel进行读和写的工具——openpyxl。需要注意的是openpyxl只支持xlsx格式的Excel表格,如果要访问xls老格式的Excel表格,仍然需要用到xlrd,xlwt。
安装和导入
仍然一如既往地使用pip安装:
pip install openpyxl使用import导入模块验证是否安装成功,还可以通过__version__属性可以查看当前版本:
import openpyxl
print('version:',openpyxl.__version__)
运行结果:
version: 3.1.2在使用前我们先初步了解下Excel表格的结构:
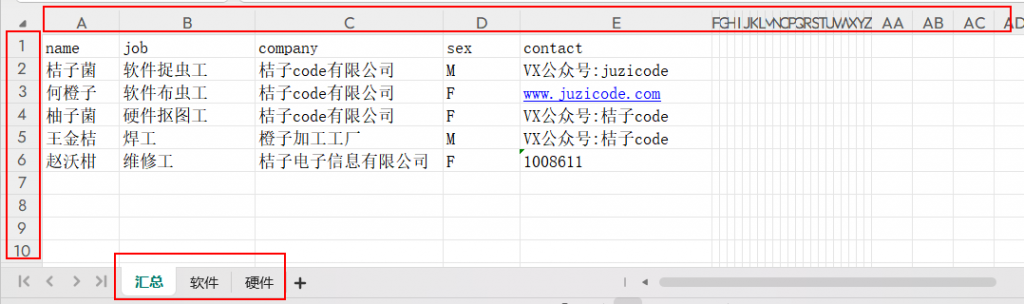
一个xlsx格式的Excel表格由多个工作表组成,上图有3个工作表:汇总,软件,硬件,每个工作表由多个单元格构成,单元格的位置可以用列标签和行标签标识,其中列标签从字符串A-Z,AA-ZZ,AAA-ZZZ,行从数字1到1,048,576。整个工作表可以看做是一个二维矩阵。
用法入门
和xlrd,xlwt等访问Excel文件一样,openpyxl访问Excel表格当然也是三步走,第1步访问文件(生成Workbook对象,工作簿),第2步访问工作表(生成Worksheet对象,工作表),第3步访问单元格(生成Cell对象,单元格)。下面是一个从文件读取表格的例子:
#juzicode.com/VX公众号:juzicode
from openpyxl import load_workbook
wb = load_workbook('profile.xlsx') # 第1步访问文件,生成一个Workbook对象
ws = wb.active # 第2步访问工作表,active表示当前活动页
print('A1单元格:', ws['A1'].value) # 第3步访问单元格
print('A2单元格:', ws['A2'].value)
print('E2单元格:', ws['E2'].value)运行结果:
A1单元格: name
A2单元格: 桔子菌
E2单元格: VX公众号:juzicode上面的例子中第1步用 load_workbook ()打开excel文件,生成一个Workbook()文件实例wb,第2步ws=wb.active表示要访问当前工作簿的活动页,得到一个Worksheet实例,第3步用ws[‘单元格位置’]表示访问的单元格,使用它的value属性可以得到单元格的内容。
如果要修改单元格可以直接修改value属性的值:
ws['E2'].value = 'juzicode.com'
print('修改后E2单元格:', ws['E2'].value)运行结果:
修改后E2单元格: juzicode.com在上面的例子中第2步使用了wb.active表示访问工作簿的当前活动页,有时一个文件包含了多个工作表,也可以通过工作表的名称来访问。如果不清楚工作表的名称,可以用第1步生成的Workbook()的sheetnames属性得到所有的工作表名称。
#juzicode.com/VX公众号:juzicode
from openpyxl import load_workbook
wb = load_workbook('profile.xlsx')
sheets = wb.sheetnames # 获取所有工作表名称
print('包含的工作表名称:',sheets)
ws = wb['汇总'] # 第2步通过工作表名称访问
print('A1单元格:', ws['A1'].value)
print('A2单元格:', ws['A2'].value)
print('E2单元格:', ws['E2'].value) 运行结果:
包含的工作表名称: ['汇总', '软件', '硬件']
A1单元格: name
A2单元格: 桔子菌
E2单元格: VX公众号:juzicode如果要保存文件,直接使用Workbook()的save()方法,传入文件名称即可:
#juzicode.com/VX公众号:juzicode
from openpyxl import load_workbook
wb = load_workbook('profile.xlsx')
sheets = wb.sheetnames # 获取所有工作表名称
ws = wb['汇总'] # 第2步通过工作表名称访问
print('E2单元格:', ws['E2'].value)
ws['E2'].value = 'juzicode.com' # 修改
print('修改后E2单元格:', ws['E2'].value)
wb.save('profile-修改后.xlsx') #写文件打开新建的excel表格可以看到表格内容E2单元格发生了变化。
前面的例子用load_workbook()方法从文件中获取表格同时生成了一个Workbook()实例,在某些场景下可能并不是从文件读取表格,而是需要”凭空“生成一个新的表格,这时就可以使用 Workbook() 生成一个wb实例,再在此基础上添加、修改表格内容:
#juzicode.com/VX公众号:juzicode
from openpyxl import Workbook
wb = Workbook()
ws = wb.create_sheet("汇总")
print('新建表格E2单元格:', ws['E2'].value) # 新建单元格内容为None
ws['E2'].value = 'juzicode.com' # 修改
print('修改后E2单元格:', ws['E2'].value)
wb.save('profile-修改后.xlsx') #写文件
多行/多列读出
除了使用单元格的方式单个读取或者写入,openpyxl还支持整行或者整列的读出,这需要用到Worksheet的iter_rows()和iter_cols()方法:
#juzicode.com/VX公众号:juzicode
from openpyxl import load_workbook
wb = load_workbook('profile.xlsx') # 第1步访问文件
ws = wb['软件'] # 第2步访问工作表
print('多行访问:')
for row in ws.iter_rows(): # 迭代读出
print(row)
print('多列访问:')
for col in ws.iter_cols(): # 迭代读出
print(col)运行结果:
多行访问:
(<Cell '软件'.A1>, <Cell '软件'.B1>, <Cell '软件'.C1>, <Cell '软件'.D1>, <Cell '软件'.E1>)
(<Cell '软件'.A2>, <Cell '软件'.B2>, <Cell '软件'.C2>, <Cell '软件'.D2>, <Cell '软件'.E2>)
(<Cell '软件'.A3>, <Cell '软件'.B3>, <Cell '软件'.C3>, <Cell '软件'.D3>, <Cell '软件'.E3>)
多列访问:
(<Cell '软件'.A1>, <Cell '软件'.A2>, <Cell '软件'.A3>)
(<Cell '软件'.B1>, <Cell '软件'.B2>, <Cell '软件'.B3>)
(<Cell '软件'.C1>, <Cell '软件'.C2>, <Cell '软件'.C3>)
(<Cell '软件'.D1>, <Cell '软件'.D2>, <Cell '软件'.D3>)
(<Cell '软件'.E1>, <Cell '软件'.E2>, <Cell '软件'.E3>)这种方法获取到的是单元格实例,还可以进一步地通过访问Cell对象的value属性获取到单元格的内容:
for row in ws.iter_rows(): # 迭代读出
for r in row:
print(r.value)如果不想返回单元格实例而是返回单元格的值,也可以在调用Worksheet的iter_rows()和iter_cols()方法时传入入参values_only=True,就能直接得到单元格的值:
#juzicode.com/VX公众号:juzicode
from openpyxl import load_workbook
wb = load_workbook('profile.xlsx') # 第1步访问文件
ws = wb['软件'] # 第2步访问工作表
print('多行访问:')
for row in ws.iter_rows(values_only=True): # 迭代读出
print(row)
print('多列访问:')
for col in ws.iter_cols(values_only=True): # 迭代读出
print(col)运行结果:
多行访问:
('name', 'job', 'company', 'sex', 'contact')
('桔子菌', '软件捉虫工', '桔子code有限公司', 'M', 'VX公众号:juzicode')
('何橙子', '软件布虫工', '桔子code有限公司', 'F', 'www.juzicode.com')
多列访问:
('name', '桔子菌', '何橙子')
('job', '软件捉虫工', '软件布虫工')
('company', '桔子code有限公司', '桔子code有限公司')
('sex', 'M', 'F')
('contact', 'VX公众号:juzicode', 'www.juzicode.com')当然你还可以在调用iter_rows()和iter_cols()方法时填写min_row,max_row等参数指定访问表格的范围,范围限定在这些指定值的闭区间。
#juzicode.com/VX公众号:juzicode
from openpyxl import load_workbook
wb = load_workbook('profile.xlsx') # 第1步访问文件
ws = wb['汇总'] # 第2步访问工作表
print('多行访问:')
for row in ws.iter_rows(values_only=True, min_row=1, max_row=3, min_col=2, max_col=5): # 迭代读出
print(row)运行结果:
多行访问:
('job', 'company', 'sex', 'contact')
('软件捉虫工', '桔子code有限公司', 'M', 'VX公众号:juzicode')
('软件布虫工', '桔子code有限公司', 'F', 'www.juzicode.com')整行追加写入
通过Worksheet的append()方法,可以实现整行追加写入:
#juzicode.com/VX公众号:juzicode
from openpyxl import Workbook
wb = Workbook()
ws = wb.active
ws.append([1,2,3,4,5]) # 列表
ws.append((10,20,30,40,50)) # 元组
wb.save('output-append.xlsx')append方法的入参除了列表和元组还可以使用字典类型,字典的key用来表示列的位置,key可以是整型或者字符串:
#juzicode.com/VX公众号:juzicode
from openpyxl import Workbook
wb = Workbook()
ws = wb.active
ws.append({1:'VX:桔子code',2:'juzicode.com',3:'aaa'}) # 整数作为key
ws.append({'A':'VX:juzicode','E':11,'ZZZ':12}) # 字符串作为key
ws.append({'A':'VX:juzicode','E':11,3:99}) # 混合方式
wb.save('output-append-dict.xlsx')虽然Excel表格列有最大数值限制(26+26*26+26*26*26),但是在当前版本下即使使用了大于该数值的整数作为字典key却不会报错。如果使用字典作为append()方法的入参,桔子菌推荐大家优先使用字符串方式指定列,当key值不在A~ZZZ的范围内时,底层会报异常处理。
新增、删除、拷贝工作表
Workbook还有一些创建工、删除、拷贝工作表,获取工作表索引等方法:
#juzicode.com/VX公众号:juzicode
from openpyxl import Workbook
wb = Workbook()
wb.create_sheet('ws1')
wb.create_sheet('ws2')
print('wb.worksheets:',wb.worksheets) # 包含的所有工作表实例
print('wb.sheetnames:',wb.sheetnames) # 包含的所有工作表名称
i = wb.index(wb['ws2']) # 获取工作表的index
print('ws2 的index:', i )
wb.copy_worksheet(wb['ws2']) # 拷贝工作表
print('拷贝ws2后,wb.sheetnames:',wb.sheetnames)
wb.remove(wb['ws2']) # 删除工作表
print('删除ws2后,wb.sheetnames:',wb.sheetnames) 运行结果:
wb.worksheets: [<Worksheet "Sheet">, <Worksheet "ws1">, <Worksheet "ws2">]
wb.sheetnames: ['Sheet', 'ws1', 'ws2']
ws2 的index: 2
拷贝ws2后,wb.sheetnames: ['Sheet', 'ws1', 'ws2', 'ws2 Copy']
删除ws2后,wb.sheetnames: ['Sheet', 'ws1', 'ws2 Copy']插入、删除行列
使用insert_rows等方法可以对表格进行行列的插入、删除:
#juzicode.com/VX公众号:juzicode
from openpyxl import load_workbook
wb = load_workbook('profile.xlsx')
ws = wb['汇总']
print('dimensions:',ws.dimensions)
ws.insert_rows(3) # 在第3行插入1行
ws.insert_cols(3,2) # 在第3列插入2列
print('dimensions-插入:',ws.dimensions) # 通过dimensions对比参考增加情况
wb.save('profile-插入行列.xlsx')
wb = load_workbook('profile.xlsx')
ws = wb['汇总']
print('dimensions:',ws.dimensions)
ws.delete_rows(3,2) # 在第3行删除2行
ws.delete_cols(2) # 在第2列删除1列
print('dimensions-删除:',ws.dimensions) # 通过dimensions对比参考增加情况
wb.save('profile-删除行列.xlsx')
运行结果:
dimensions: A1:E6
dimensions-插入: A1:G7
dimensions: A1:E6
dimensions-删除: A1:D4从运行结果打印的dimensions属性可以看到行列增减的情况,也可以通过打开新生成的Excel文件看到插入删除行列的效果。
设置样式
前面介绍的内容可以完成表格基本内容的“增删改查”,如果要美化表格的“外观”,还需要用到样式设置功能。
1)字体样式设置
用Font()创建的对象赋值给单元格的font属性,就可以完成单元格属性的设置。创建Font()对象时,有可选的color,size,name,bold等入参:
#juzicode.com/VX公众号:juzicode
from openpyxl import load_workbook
from openpyxl.styles import Font
wb = load_workbook('profile.xlsx')
ws = wb.active
ws['A1'].font = Font(color="FF0000") # 设置字体为红色
ws['B1'].font = Font(color="00FF00") # 设置字体为绿色
ws['C1'].font = Font(color="0000FF") # 设置字体为蓝色
ws['A2'].font = Font(size=15) # 字号大小为15
ws['B2'].font = Font(size=17) # 字号大小为17
ws['C2'].font = Font(size=19) # 字号大小为19
#其他字体属性设置
ws['A3'].font = Font(name='仿宋', # 字体样式
color="FF0000", # 颜色
size=15, # 大小
bold=True, # 是否加粗
italic=True, # 是否斜体
strike=True, # 是否使用删除线
underline='double', # 下划线样式,可选{'doubleAccounting', 'double', 'single', 'singleAccounting'}
)
wb.save('profile-字体.xlsx')运行结果:
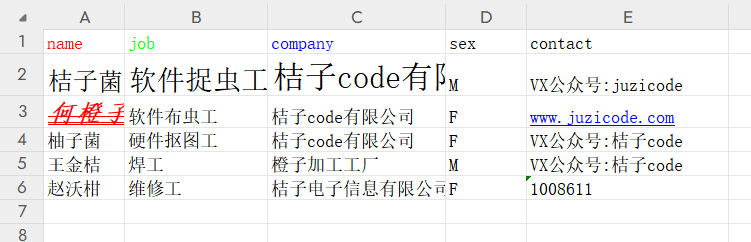
2)对齐方式设置
和字体设置类似, 用Alignment()创建的对象赋值给单元格的alignment属性,就可以完成单元格属性的设置。创建Alignment()对象时,有可选的horizontal,vertical,wrap_text等入参:
#juzicode.com/VX公众号:juzicode
from openpyxl import load_workbook
from openpyxl.styles import Alignment
wb = load_workbook('profile.xlsx')
ws = wb.active
# 设置行列宽高
ws.row_dimensions[2].height = 30
ws.row_dimensions[3].height = 30
ws.column_dimensions['A'].width = 16
ws.column_dimensions['C'].width = 16
# 水平对齐
ws['A1'].alignment = Alignment(horizontal="left") # 靠左对齐
ws['B1'].alignment = Alignment(horizontal="right") # 靠右对齐
ws['C1'].alignment = Alignment(horizontal="center") # 中间对齐
#其他对齐属性设置
ws['A3'].alignment = Alignment(horizontal='right', # 水平对齐
vertical="top", # 垂直对齐
wrap_text=True, # 自动换行
text_rotation=0, # 旋转角度
indent=1, # 缩进
shrink_to_fit=True, # 是否自动缩小
)
ws['C3'].alignment = Alignment(horizontal='right', # 水平对齐
vertical="top", # 垂直对齐
wrap_text=False, # 自动换行
text_rotation=0, # 旋转角度
indent=1, # 缩进
shrink_to_fit=True, # 是否自动缩小 wrap_text设置为False才能看到效果
)
wb.save('profile-对齐.xlsx')运行结果:
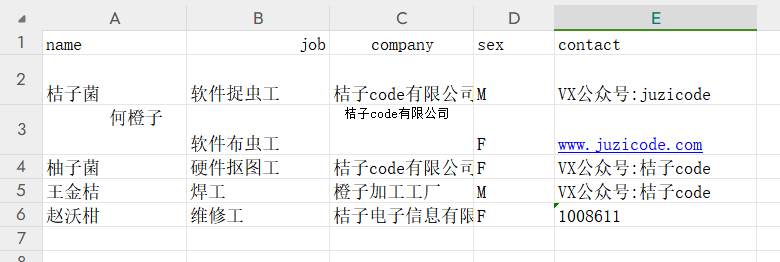
3)填充
用普通填充PatternFill()或渐变填充GradientFill()修改单元格的fill属性,达到修改填充样式的目的:
#juzicode.com/VX公众号:juzicode
from openpyxl import load_workbook
from openpyxl.styles import PatternFill,GradientFill
wb = load_workbook('profile.xlsx')
ws = wb.active
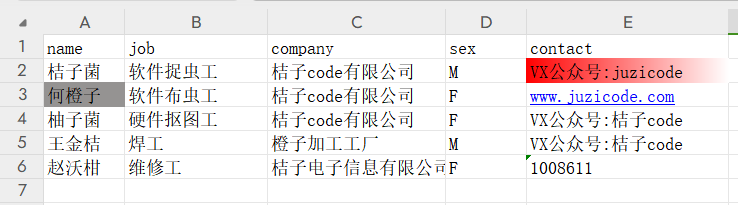
ws['A3'].fill = PatternFill(fill_type='solid',fgColor='959392')
ws['E2'].fill = GradientFill(stop=('FF0000','FFFFFF'))
wb.save('profile-填充.xlsx')运行结果:
4)边框
先用Side()创建边界实例side,再将side传给Border()的top,bottom等入参。其中side的style入参决定了边界的样式,color决定其颜色:
#juzicode.com/VX公众号:juzicode
from openpyxl import load_workbook
from openpyxl.styles import Border, Side
wb = load_workbook('profile.xlsx')
ws = wb.active
side = Side(style='dashed',color='FF00FF')
side2 = Side(style='thick',color='FF00FF')
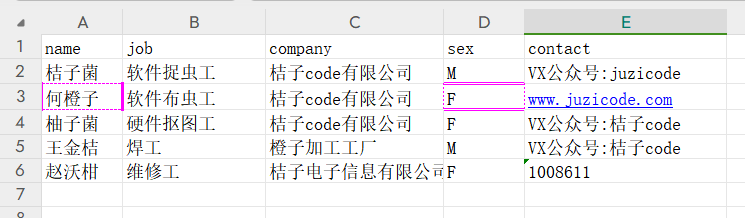
ws['A3'].border = Border(top=side,
bottom=side,
left=side2,
right=side2
)
side = Side(style='double',color='FF00FF')
side2 = Side(style='dotted',color='FF00FF')
ws['D3'].border = Border(top=side,
bottom=side,
left=side2,
right=side2
)
wb.save('profile-边框.xlsx')运行结果:
创建样式需要从openpyxl.styles导入各种样式的类。使用的方法基本相同,用样式类创建好对象,然后赋值给单元格相应的属性。
好了,今天的openpyxl就介绍到这里,bug敲起来吧。
如果你想直接用本文中的用例,又不想一块一块地复制,也可以在公众号【桔子code】后台回复【openpyxl】获取下载链接,包都打好了,拿走不谢。