错误提示:
tesseract 5.0使用官方eng.traineddata语言包和–oem 0识别时提示:TesseractError: (1, “Error: Tesseract (legacy) engine requested, but components are not present in d:\\dev\\Tesseract-OCR5.0.0\\tessdata\\eng.traineddata!! Failed loading language ‘eng’ Tesseract couldn’t load any languages! Could not initialize tesseract.”)
#juzicode.com / VX公众号:桔子code
import pytesseract as ts
lang = 'eng'
text = ts.image_to_string('bookseg.png',lang,config='--oem 0')
print(text)==========运行结果:
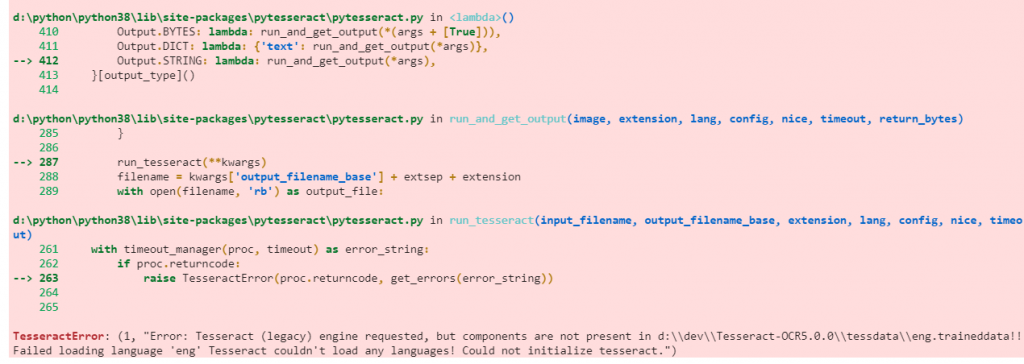
---------------------------------------------------------------------------
TesseractError Traceback (most recent call last)
<ipython-input-7-c3e604549502> in <module>
2 import pytesseract as ts
3 lang = 'eng'
----> 4 text = ts.image_to_string('bookseg.png',lang,config='--oem 0')
5 print(text)
........................
d:\python\python38\lib\site-packages\pytesseract\pytesseract.py in run_tesseract(input_filename, output_filename_base, extension, lang, config, nice, timeout)
261 with timeout_manager(proc, timeout) as error_string:
262 if proc.returncode:
--> 263 raise TesseractError(proc.returncode, get_errors(error_string))
264
265
TesseractError: (1, "Error: Tesseract (legacy) engine requested, but components are not present in d:\\dev\\Tesseract-OCR5.0.0\\tessdata\\eng.traineddata!! Failed loading language 'eng' Tesseract couldn't load any languages! Could not initialize tesseract.")
错误原因:
1、tesseract5.0配套的traineddata文件某些语言版本不支持老版本的引擎(oem=0)。
解决方法:
1、切换到新版本的ocr引擎,设置–oem 1:
#juzicode.com / VX公众号:桔子code
import pytesseract as ts
lang = 'eng'
#text = ts.image_to_string('bookseg.png',lang,config='--oem 0')
text = ts.image_to_string('bookseg.png',lang,config='--oem 1')
print(text)扩展内容:
如果本文还没有完全解决你的疑惑,你也可以在微信公众号“桔子code”后台给我留言,欢迎一起探讨交流。
