原文链接:http://www.juzicode.com/image-ocr-pytesseract
pytesseract是对Tesseract-OCR命令行的封装,实际上底层调用的还是tesseract可执行文件,所以在使用pytesseract前需要完成Tesseract-OCR软件安装和语言包安装,详细方法可以参考 Tesseract-OCR5.0软件安装和语言包安装(Windows系统)。
pytesseract可以通过pip安装,当前(2021.11)最新版本为0.3.8:
pip install pytesseract1、获取tesseract版本号
get_tesseract_version()获取tesseract的版本号,注意并不是pytesseract的版本号:
#juzicode.com / VX公众号:桔子code
import pytesseract as ts
version = ts.get_tesseract_version()
print('version:',version)运行结果:
version: 5.0.0-rc1.20211030结果和在命令行执行”tesseract –version”看到的版本号是一样的:
E:\juzicode\tess>tesseract --version
tesseract v5.0.0-rc1.202110302、获取语言包列表
通过get_languages()获取安装的语言包列表:
#juzicode.com / VX公众号:桔子code
import pytesseract as ts
langs = ts.get_languages()
print('langs:',langs)运行结果:
langs: ['chi_sim', 'eng', 'osd']和在命令行用“tesseract –list-langs”检查语言包得到的结果是一样的:
E:\juzicode\tess>tesseract --list-langs
List of available languages (3):
chi_sim
eng
osd3、识别图片中的文字
image_to_string()用来识别图片中的文字,最简单的用法传入2个入参,一个是图片的文件名称,一个是识别所用的语言包类型,比如要识别下图中的文字,这是一段从pdf文件中截屏的片段,文件名为bookseg.png,语言包选择chi_sim:

img_fn = 'bookseg.png'
lang = 'chi_sim'
text = ts.image_to_string(img_fn,lang)
print(text)运行结果:
引 言
数 字 图 像 处 理 方 法 的 重 要 性 源 于 两 个 主 要 应 用 领 域 : 改 善 图 示 信 息 以 便 人 们 解 释 ; 为 存 储 、 传
输 和 表 示 而 对 图 像 数 据 进 行 处 理 , 以 便 于 机 器 自 动 理 解 。 本 章 有 几 个 主 要 目 的 : (1) 定 义 我 们 称 之 为
图 像 处 理 领 域 的 范 围 ; (2) 从 历 史 观 点 回 顾 图 像 处 理 的 起 源 ; (3) 通 过 考 察 一 些 主 要 的 应 用 领 域 , 给 出
图 像 处 理 技 术 状 况 的 概 念 ; (4) 筒 要 讨 论 数 字 图 像 处 理 中 所 用 的 主 要 方 法 ; (5) 概 述 通 用 目 的 的 典 型 图
像 处 理 系 统 的 组 成 ; (6) 列 出 公 开 发 表 的 数 字 图 像 处 理 领 域 的 一 些 图 书 和 文 献 。从这个例子可以看到识别清晰度较高的图片效果还是非常好的。
除了前面介绍的传入图片文件名称的方法,还可以传入图像的numpy数组,这样就可以和pillow、opencv等模块配合使用,在某些场合下就可以先用pillow或opencv等做一些预处理再传入到image_to_string()中识别。
img_fn = 'bookseg.png'
lang = 'chi_sim'
img = cv2.imread(img_fn,0)
cv2.imwrite('gray-bin.jpg',img)
text = ts.image_to_string(img,lang) #第1个参数传入numpy类型
print(text)image_to_string()还可以用config参数配置tesseract的命令选项,所有的可选参数组成一个字符串传给config入参,使用方法为:
text = ts.image_to_string(img,lang,config='--psm 6 --oem 1 --loglevel ALL')详细的参数选项有如下几种,可以通过tesseract的help命令查询到:
OCR options:
--tessdata-dir PATH Specify the location of tessdata path.
--user-words PATH Specify the location of user words file.
--user-patterns PATH Specify the location of user patterns file.
--dpi VALUE Specify DPI for input image.
--loglevel LEVEL Specify logging level. LEVEL can be
ALL, TRACE, DEBUG, INFO, WARN, ERROR, FATAL or OFF.
-l LANG[+LANG] Specify language(s) used for OCR.
-c VAR=VALUE Set value for config variables.
Multiple -c arguments are allowed.
--psm NUM Specify page segmentation mode.
--oem NUM Specify OCR Engine mode.
NOTE: These options must occur before any configfile.4、获取图片中文字的详细信息
image_to_data()用来获取识别出来的文字的详细信息,包含识别到的文本内容,可信度,位置等:
img_fn = 'bookseg.png'
lang = 'chi_sim'
data = ts.image_to_data(img_fn,lang)
print(data)运行结果:
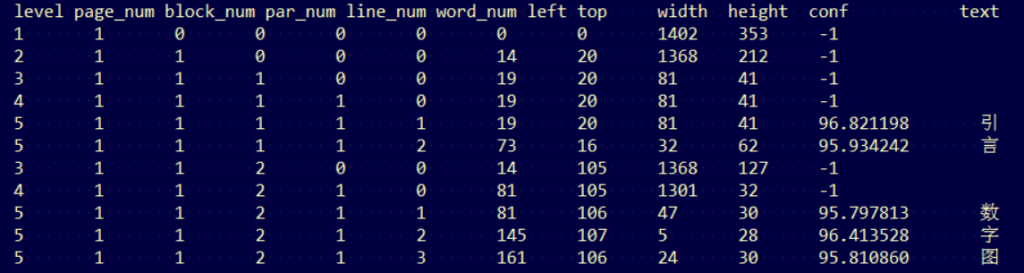
最后一列是识别出来的文本内容,往前一列是识别出来的可信度,再往前4列是在图片中的位置,包含left,top,width,height等4个要素。
注意image_to_data()返回的是str类型的数据,如果要使用其中的conf可信度,left,top等位置信息,还需要经过提取、转换才能得到。
5、识别图片中的文字和位置
image_to_boxes()用来获取识别出来的文字和位置信息:
img_fn = 'bookseg.png'
lang = 'chi_sim'
boxes = ts.image_to_boxes(img_fn,lang)
print(boxes)运行结果:
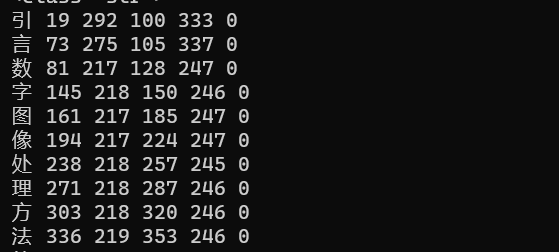
这种方法得到的位置信息和image_to_data()中得到的left,top,width,height位置信息是一样的。同样image_to_data()返回的结果也是一个字符串,如果要使用其中的单个字符和位置信息,也需要进行提取和转换。
6、识别osd信息
image_to_osd()返回识别到的osd信息:
img_fn = 'bookseg.png'
lang = 'chi_sim'
osd = ts.image_to_osd(img_fn,lang)
print(osd)
print(type(osd))运行结果:
Page number: 0
Orientation in degrees: 0
Rotate: 0
Orientation confidence: 37.74
Script: Han
Script confidence: 1.43
<class 'str'>7、识别并生成xml文件
image_to_pdf_or_hocr()可以将识别的文字信息转为xml格式字节流,从而可以写入到xml文件中,其中入参extension设置为’hocr’:
img_fn = 'bookseg.png'
lang = 'chi_sim'
hocr = ts.image_to_pdf_or_hocr(img_fn, lang, extension='hocr')
with open('test.xml', 'w+b') as f:
f.write(hocr)
print(type(hocr))调用image_to_pdf_or_hocr()返回的数据类型为bytes类型,这点和前面几种方法的返回结果是有差异的,bytes类型可以用wb方式写入到文件,写入完成后打开文件可以看该文件包含了识别文字、可信度、位置信息等内容:
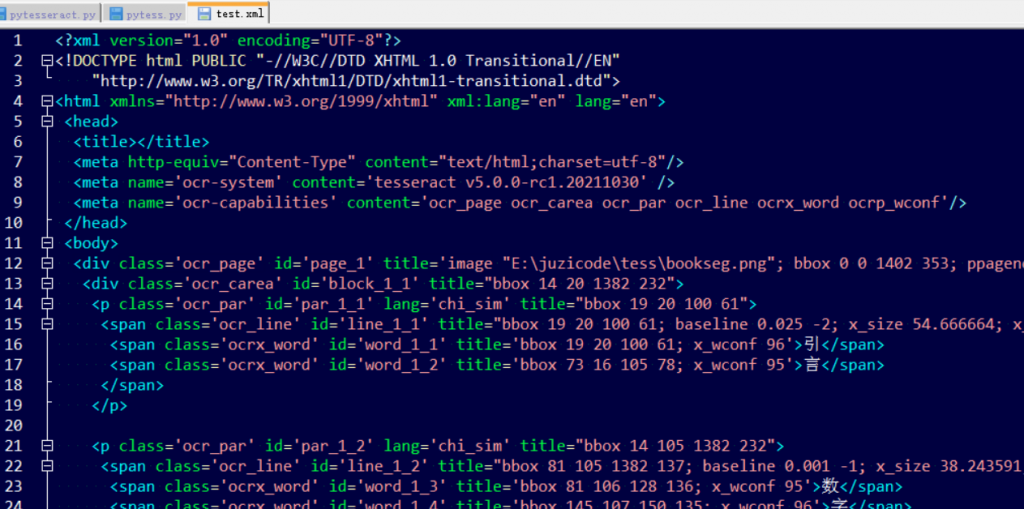
避坑指南:
1、提示tesseract未安装错误:
import pytesseract as ts
version = ts.get_tesseract_version()
print('version:',version)
======运行结果
FileNotFoundError: [WinError 2] 系统找不到指定的文件。
......
pytesseract.pytesseract.TesseractNotFoundError: tesseract is not installed or it's not in your PATH. See README file for more information.原因:一个是没有安装tesseract命令行工具,一个是安装完后没有把安装路径添加到PATH系统变量中。
2、获取不到支持的语言包:
img_fn = 'bookseg.png'
lang = 'chi_sim'
text = ts.image_to_string(img_fn,lang,config='--tessdata-dir d:\\dev\\Tesseract-OCR5.0.0\\tessdata')
print(text)
======运行结果
pytesseract.pytesseract.TesseractError: (1, 'Error opening data file d:devTesseract-OCR5.0.0tessdata/chi_sim.traineddata Please make sure the TESSDATA_PREFIX environment variable is set to your "tessdata" directory. Failed loading language \'chi_sim\' Tesseract couldn\'t load any languages! Could not initialize tesseract.')使用config参数指定语言包路径时,不能使用右斜杠,只能使用左斜杠。
#text = ts.image_to_string(img_fn,lang,config='--tessdata-dir d:\\dev\\Tesseract-OCR5.0.0\\tessdata')
text = ts.image_to_string(img_fn,lang,config='--tessdata-dir d:/dev/Tesseract-OCR5.0.0/tessdata')3、使用–oem 0选项时提示不支持老版本的ocr引擎,需要切换为–oem 1或者不指明oem默认使用新的ocr引擎:
img_fn = 'bookseg.png'
lang = 'eng'
text = ts.image_to_string(img_fn,lang,config='--oem 0')
======运行结果
pytesseract.pytesseract.TesseractError: (1, "Error: Tesseract (legacy) engine requested,
but components are not present in d:\\dev\\Tesseract-OCR5.0.0/tessdata/eng.traineddata!!
Failed loading language 'eng' Tesseract couldn't load any languages! Could not initialize tesseract.")