内容目录
本文介绍图像统计功能相关的函数,包含统计元素中非零值的数量、最小值、最大值、和、均值、标准差,以及单行或单列的最小值、最大值、和、均值。
1、非0值数量 countNonZero
countNonZero()用来统计元素值为非0值的像素点个数。
接口形式:
cv2.countNonZero(src) -> retval- 参数含义:
- src:输入图像,必须为单通道图像;
- retval:非零像素值个数
下面是一个统计lena灰度图和一个5×5对角矩阵中非零元素数量的例子:
import numpy as np
import cv2
print('VX公众号: 桔子code / juzicode.com')
print('cv2.__version__:',cv2.__version__)
img_src = cv2.imread('..\\samples\\data\\lena.jpg',cv2.IMREAD_GRAYSCALE)
count = cv2.countNonZero(img_src)
print('非零像素点个数:',count)
arr = np.eye(5)
print('np.eye(5):\n',arr)
count = cv2.countNonZero(arr)
print('非零像素点个数:',count)
运行结果:
VX公众号: 桔子code / juzicode.com
cv2.__version__: 4.5.3
非零像素点个数: 262144
np.eye(5):
[[1. 0. 0. 0. 0.]
[0. 1. 0. 0. 0.]
[0. 0. 1. 0. 0.]
[0. 0. 0. 1. 0.]
[0. 0. 0. 0. 1.]]
非零像素点个数: 5这个5×5的对角阵,只有对角线上的5个元素非零,得到的非零像素点个数为5。
用absdiff()计算了2幅图像差异后得到的新图像,再用countNonZero()计算这个新图像中非0的像素点个数,可以比较出2幅图像的差异,OpenCV-Python教程:形态学变换~开闭操作,顶帽黑帽,形态学梯度,击中击不中(morphologyEx) 中比较开操作和先腐蚀后膨胀图像差异时有具体的例子。
OpenCV 4.5版本中虽然没有提供零值元素数量的统计函数,但是零值元素数量可以由元素总数减去非零值数量得到:
arr = np.eye(5)
print('np.eye(5):\n',arr)
count = cv2.countNonZero(arr)
count_zero = arr.shape[0]*arr.shape[0]-count
print('非零像素点个数:',count)
print('零像素点个数:',count_zero) 运行结果:
np.eye(5):
[[1. 0. 0. 0. 0.]
[0. 1. 0. 0. 0.]
[0. 0. 1. 0. 0.]
[0. 0. 0. 1. 0.]
[0. 0. 0. 0. 1.]]
非零像素点个数: 5
零像素点个数: 20
2、最小最大值及其位置 minMaxLoc
minMaxLoc()函数返回图像中的元素值的最小值和最大值,以及最小值和最大值的坐标。
接口形式:
cv2.minMaxLoc(src[, mask])->minVal, maxVal, minLoc, maxLoc- 参数含义:
- src:输入图像,必须为单通道图像;
- mask:掩码;
- minVal, maxVal, minLoc, maxLoc:依次为最小值,最大值,最小值的坐标,最大值的坐标;
下面是一个求lena图像R通道极值的例子:
import cv2
print('VX公众号: 桔子code / juzicode.com')
img = cv2.imread('..\\lena.jpg')[:,:,2] #提取其中R通道
ret = cv2.minMaxLoc(img)
print('minMaxLoc(img): ',ret) 运行结果:
minMaxLoc(img): (49.0, 255.0, (265, 198), (415, 8))返回结果是一个4元组,第0个元素为最小值,第1个元素为最大值,第2个元素为最小值的坐标:(265, 198),第3个元素是最大值的坐标:(415, 8)。
返回minLoc和maxLoc的坐标位置是以OpenCV中(x,y)的形式组织的,但是在numpy中下标访问是按照array[行][列]形式,类似于array[y][x]的形式,所以minLoc和maxLoc的坐标值不能直接用于numpy的下标访问,需要对调后才可以使用,通过下面的例子可以得到验证,在前面的例子中极值的位置是(265, 198), (415, 8):
#错误的下标访问,未对调的方式
print('img[265][198]:',img[265][198])
print('img[415][8]:',img[415][8])
#正确的下标访问,对调后作为numpy数组下标
print('img[198][265]:',img[198][265])
print('img[8][415]:',img[8][415])运行结果:
minMaxLoc(img): (49.0, 255.0, (265, 198), (415, 8))
img[265][198]: 90
img[415][8]: 171
img[198][265]: 49 #对调后的下标访问得到正确的最小值
img[8][415]: 255 #对调后的下标访问得到正确的最大值如果存在多个最大值或者最小值,返回是谁的位置?
minMaxLoc()内部是按照行扫描方式,如果找到一个最小值,后面没有比这个数值更小的数值,那最小值的位置就是最开始出现的那个位置,即使后面出现了这个最小数值相等的数值,找最大值也一样。比如一串数字1,2,3,4,5,1,7,这里最小值为1,最小值的位置就是第1个数值1,即使后面第6个数值也为1。扫描完上一行之后再扫描下一行,即使后面的行出现相等数值也不会改变原来找到的最小值或最大值的位置。下面是一个存在多个最大值或最小值的例子:
import numpy as np
import cv2
print('cv2.__version__:',cv2.__version__)
print('VX公众号: 桔子code / juzicode.com')
arr = np.array([[1,1,0,2,0],[0,20,20,11,15]])
print('arr:\n',arr)
ret = cv2.minMaxLoc(arr)
print('minMaxLoc(arr): ',ret) 运行结果:
VX公众号: 桔子code / juzicode.com
arr:
[[ 1 1 0 2 0]
[ 0 20 20 11 15]]
minMaxLoc(arr): (0.0, 20.0, (2, 0), (1, 1))这个例子中第0行和第1行都有最小值0,扫描时先将第0行第2列的0的位置保留下来,后面如果没有小于0的数值,这个位置值就不再变化;同样地找到第1行第1列的20时,后面没有比20更大的数值,所以最大值的位置就是第1行第1列。
3、元素值之和sumElems
sumElems()统计所有元素值之和,如果有多通道,分通道计算,返回的是一个四元组,依次对应图像可能包含的第0,1,2,3通道,如果单通道图像则只有下标0对应的元素有意义,如果是3通道则只有前3个元素有意义。
接口形式:
cv2.sumElems(src) -> retval- 参数含义:
- src:输入图像,可以是单通道,3通道或4通道图像;
- retval:返回的是一个4元组,分别对应各通道元素的和。
注意在C++接口中,函数的名称为sum(),对应的接口形式为:
Scalar cv::sum(InputArray src)下面是一个统计lena图和一个5×5对角阵中所有元素和的例子:
import numpy as np
import cv2
print('VX公众号: 桔子code / juzicode.com')
print('cv2.__version__:',cv2.__version__)
img_src = cv2.imread('..\\samples\\data\\lena.jpg')#,cv2.IMREAD_GRAYSCALE)
val = cv2.sumElems(img_src)
print('lena像素元素和:',val )
arr = np.eye(5)
val = cv2.sumElems(arr)
print('np.eye(5)元素和:',val) 运行结果:
lena像素元素和: (27629713.0, 26099764.0, 47115221.0, 0.0)
np.eye(5)元素和: (5.0, 0.0, 0.0, 0.0)这个例子中lena图像读出后是一个3通道彩色图像,所以用sumElems()计算和后,返回结果的下标0,1,2对应其B,G,R通道的元素的和,其下标3的值为0.0没有意义,np.eye(5)生成的是“单通道图像”,返回结果只有其下标为0的值才有意义。
4、平均值mean
mean()用来统计单个通道内像素值的平均值,如果有多个通道,分通道计算。
接口形式:
cv2.mean(src[, mask]) ->retval- 参数含义:
- src:输入图像,可以是单通道,3通道或4通道图像;
- mask:可选的掩码;
- retval:返回的是一个4元组,分别对应各通道元素的平均值。
下面这个例子计算lena图和5×5对角阵中所有元素的平均值:
import numpy as np
import cv2
print('VX公众号: 桔子code / juzicode.com')
print('cv2.__version__:',cv2.__version__)
img_src = cv2.imread('..\\samples\\data\\lena.jpg')
val = cv2.mean(img_src)
print('lena像素平均值:',val)
arr = np.eye(5)
val = cv2.mean(arr)
print('np.eye(5)平均值:',val) 运行结果:
lena像素平均值: (105.39899063110352, 99.56269836425781, 179.73030471801758, 0.0)
np.eye(5)平均值: (0.2, 0.0, 0.0, 0.0)返回结果也是一个四元组,可以参考sumElems()理解。
5、平均值与标准差meanStdDev
meanStdDev()用来统计单通道内像素值的平均值和标准差,一次调用返回2个结果。
接口形式:
cv2.meanStdDev(src[, mean[, stddev[, mask]]]) ->mean, stddev- 参数含义:
- src:输入图像,必须为单通道图像;
- mask:可选的掩码;
- mean:平均值;
- stddev:标准差;
meanStdDev()返回的是一个元组,下标0为平均值mean,下标1为标准差stddev。
下面这个例子计算lena图和5×5对角阵中元素的平均值和标准差:
import numpy as np
import cv2
print('VX公众号: 桔子code / juzicode.com')
print('cv2.__version__:',cv2.__version__)
img_src = cv2.imread('..\\samples\\data\\lena.jpg')#,cv2.IMREAD_GRAYSCALE)
val = cv2.meanStdDev(img_src)
print(type(val))
print('val[0]:',type(val[0]))
print('val[0][0]:',type(val[0][0]))
print('lena图像的平均值:\n',val[0])
print('lena图像的标准差:\n',val[1])
print('lena图像B通道的平均值:\n',val[0][0][0])
print('lena图像B通道的标准差:\n',val[1][0][0])
arr = np.eye(5)
val = cv2.meanStdDev(arr)
print('np.eye(5)的平均值:',val[0])
print('np.eye(5)的标准差:',val[1])
print('np.eye(5)的平均值:',val[0][0][0])
print('np.eye(5)的标准差:',val[1][0][0])运行结果:
<class 'tuple'>
val[0]: <class 'numpy.ndarray'>
val[0][0]: <class 'numpy.ndarray'>
lena图像的平均值:
[[105.39899063]
[ 99.56269836]
[179.73030472]]
lena图像的标准差:
[[33.74205485]
[52.87345828]
[49.01569488]]
lena图像B通道的平均值:
105.39899063110352
lena图像B通道的标准差:
33.74205485167219
np.eye(5)的平均值: [[0.2]]
np.eye(5)的标准差: [[0.4]]
np.eye(5)的平均值: 0.2
np.eye(5)的标准差: 0.4从上面的例子也可以看到,meanStdDev()返回的元组中,下标0是平均值,下标1是标准差。平均值或标准差是一个numpy.ndarray类型的数据,其数组大小跟原始图像通道数一样,比如前面例子中lena图像的通道数是3,5×5对角阵的通道数是1。平均值和标准差中的某一个通道的数值仍然是numpy.ndarray类型的数据,其数组大小为1。所以当要取其某一个通道的数值时,则需要用3次下标的方式才能得到,比如用val[0][0][0]才能得到其B通道的平均值,这里第1个0表示返回结果的第0个元素,第2个0表示图像通道0,第3个0为下标固定值。
对比mean()方法计算的平均值,meanStdDev()得到的平均值数值大小是一样的。但是需要注意的是mean()方法返回的是一个包含4个元素的元组,其元组长度是固定的,而meanStdDev()方法得到的平均值是一个numpy数组,包含元素的个数依赖于输入图像的通道数。
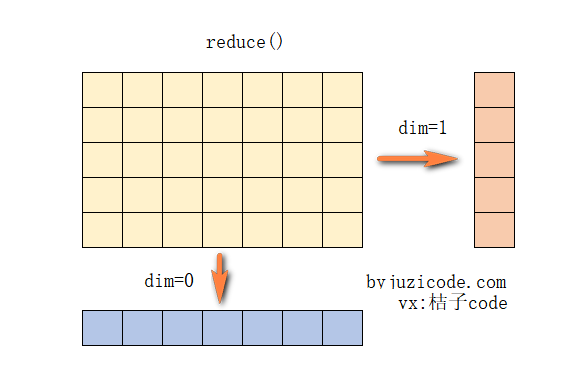
6、单行/列的极值、和、均值 reduce
reduce用来统计二维数组的每一行或每一列中的最小值、最大值、平均值、和。这里reduce的含义也可以理解为将二维矩阵压缩成一维向量,压缩后的值根据入参类型可以是最小值、最大值、平均值或者和。
接口形式:
cv2.reduce(src, dim, rtype[, dst[, dtype]]) ->dst- 参数含义:
- src:源图像,可以是单通道也可以是多通道,多通道时分通道计算;
- dim:如果为0表示统计每列的数据等价于压缩成行(row),如果为1表示统计每行的数据等价于压缩成列(column);
- rtype:reduce操作的类型;
- dst:目标图像;
- dtype:目标图像的类型,如果不指定默认为-1表示用源图像src的数据类型;
dim参数的理解:如果为0表示生成新的数据将是一个行向量,所以是在每一列上操作,将单个的列压缩成一个数值从而组成一个行向量;如果为1则表示生成新的数据是一个列向量,在每一行上操作,将单个的行压缩成一个数值从而组成一个列向量。
rtype表示的reudce操作的类型如下:
| rtype标志 | 含义 |
| REDUCE_SUM | 所有行或列的和 |
| REDUCE_AVG | 所有行或列的平均值 |
| REDUCE_MAX | 所有行或列的最大值 |
| REDUCE_MIN | 所有行或列的最小值 |
下面这个例子分别统计行和列的最小值、最大值:
import numpy as np
import cv2
print('cv2.__version__:',cv2.__version__)
print('VX公众号: 桔子code / juzicode.com')
arr = np.array([[1,1,0,2,0],[0,20,20,11,15],[5,5,5,5,5]],dtype=np.uint8)
print(arr.shape,arr.dtype)
print('arr:\n',arr)
#reduce为行向量,计算最小最大值
row_min = cv2.reduce(arr,0,cv2.REDUCE_MIN)
print('row_min: \n',row_min)
row_max = cv2.reduce(arr,0,cv2.REDUCE_MAX)
print('row_max: \n',row_max)
#reduce为列向量,计算最小最大值
col_min = cv2.reduce(arr,1,cv2.REDUCE_MIN)
print('col_min: \n',col_min)
col_max = cv2.reduce(arr,1,cv2.REDUCE_MAX)
print('col_max: \n',col_max) 运行结果:
VX公众号: 桔子code / juzicode.com
(3, 5) uint8
arr:
[[ 1 1 0 2 0]
[ 0 20 20 11 15]
[ 5 5 5 5 5]]
row_min:
[[0 1 0 2 0]]
row_max:
[[ 5 20 20 11 15]]
col_min:
[[0]
[0]
[5]]
col_max:
[[ 2]
[20]
[ 5]]下面这个例子计算和、均值:
import numpy as np
import cv2
print('cv2.__version__:',cv2.__version__)
print('VX公众号: 桔子code / juzicode.com')
arr = np.array([[1,1,0,2,0],[0,20,20,11,15],[5,5,5,5,5]],dtype=np.uint8)
print(arr.shape,arr.dtype)
print('arr:\n',arr)
#reduce为行向量,计算和、均值
row_sum = cv2.reduce(arr,0,cv2.REDUCE_SUM,dtype=cv2.CV_32S)
print('row_sum: \n',row_sum)
row_avg = cv2.reduce(arr,0,cv2.REDUCE_AVG,dtype=cv2.CV_32F)
print('row_avg: \n',row_avg)
#reduce为列向量,计算和、均值
col_sum = cv2.reduce(arr,1,cv2.REDUCE_SUM,dtype=cv2.CV_32S)
print('col_sum: \n',col_sum)
col_avg = cv2.reduce(arr,1,cv2.REDUCE_AVG,dtype=cv2.CV_32F)
print('col_avg: \n',col_avg) 运行结果:
arr:
[[ 1 1 0 2 0]
[ 0 20 20 11 15]
[ 5 5 5 5 5]]
row_sum:
[[ 6 26 25 18 20]]
row_avg:
[[2. 8.666667 8.333334 6. 6.666667]]
col_sum:
[[ 4]
[66]
[25]]
col_avg:
[[ 0.8]
[13.2]
[ 5. ]]在计算和、均值的时候跟计算最大值、最小值不一样地方是入参dtype必须指定。因为最大值、最小值的数据类型仍然是原来的数据类型,可以不指定其新生成数据的类型,默认和源图像数据类型一样,所以在前一个例子中并没有指定dtype的类型。但是计算和的时候有可能会超出源数据类型所表示的范围,所以dtype再不指定就会提示错误了。
有个例外的地方是在计算均值时,如果不指定dtype的类型使用默认的源图像数据类型,虽然不会超出源图像数据类型所能表示的范围,但是均值涉及到除法和浮点计算,得到的数据精度可能是不准确的。像上面这个例子虽然也可以不指定数据类型默认用源图像的数据类型CV_8U,但是计算均值得到的是经过四舍五入后的整数,下面这个例子展示了这个差异:
#计算均值不指定类型,默认用源数据的CV_8U:
row_avg = cv2.reduce(arr,0,cv2.REDUCE_AVG)#,dtype=cv2.CV_32F)
print('row_avg: \n',row_avg)
col_avg = cv2.reduce(arr,1,cv2.REDUCE_AVG)#,dtype=cv2.CV_32F)
print('col_avg: \n',col_avg)
-----运行结果:
row_avg:
[[2 9 8 6 7]] #对比使用更高精度的数据类型: [[2. 8.666667 8.333334 6. 6.666667]]
col_avg:
[[ 1]
[13]
[ 5]]小结:countNonZero()用来统计的是非零元素的数量;minMaxLoc()返回位置参数是按照OpenCV格式组织的,在numpy数组中使用时需要对调下标组织形式,返回的坐标是按行扫描方式得到的最开始的坐标;sumElems()用来计算单个通道内所有元素的和,其原生的C接口函数为sum();meanStdDev()返回的平均值和标准差是一个numpy数组,其数组长度依赖输入图像的通道数,这点和mean()、sumElems()计算的结果默认包含4个元素有所区别;reduce()计算单行/列的和、均值时dtype类型需要指定为能精确表示的数据类型。